Paper Notes: Parameter-Efficient Fine-Tuning
A collection of lightweight fine-tuning methods.
Rough Comparison of Lightweight Fine-Tuning Methods
-
Methods:
Method Full Name Core Idea LoRA Low-Rank Adaptation Insert low-rank trainable modules into weight matrices Adapter Adapter Module Insert small trainable modules between layers Prompt Tuning Prompt / Prefix Tuning Optimize prompt vectors to guide model output BitFit Bias Term Fine-Tuning Only fine-tune bias terms QLoRA Quantized LoRA LoRA fine-tuning on quantized models to save memory Delta Tuning Delta Tuning Fine-tune specific modules (e.g., attention) -
Comparison:
Method Trainable Params Resource Needs Performance Best Use Case LoRA Few Medium High General fine-tuning Adapter Few Medium Medium-High Multi-task learning Prompt Tuning Very Few Very Low Medium Text generation/classification BitFit Very Few Very Low Low-Medium Simple/quick experiments QLoRA Few Low High Large models with limited resources Delta Tuning Few Medium Medium Fine-tune attention or specific modules
Full Fine-Tuning: Types and Effects
-
Main approaches:
Type Description Applications Standard full fine-tuning Train all parameters Single-task adaptation Multi-stage fine-tuning General → specific task Better control & generalization Continual fine-tuning Adapt to new data over time Online/iterative learning Domain-adaptive FT Transfer pretrained models to domain data Healthcare, law, finance Instruction FT Fine-tune on instruction data Multi-task general models (e.g., Alpaca, ChatGPT) -
Comparison:
Method Resource Needs Data Needs Generalization Best Use Case Standard FT Very High Medium-High Medium Single-task Multi-stage FT High High High Multi-task transfer Continual FT Medium Growing Medium-High Online learning Domain FT Medium-High Domain data High Industry-specific Instruction FT Very High Diverse data High General LLMs
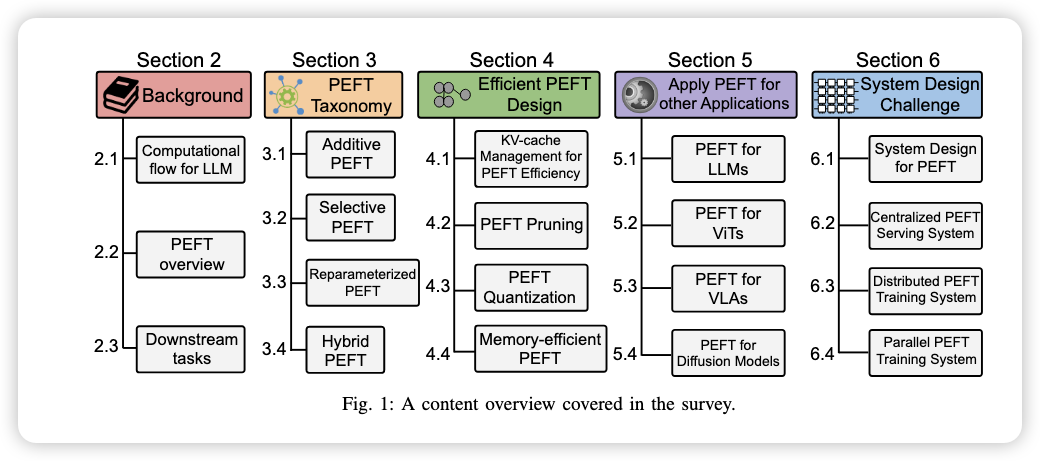
Survey on PEFT
- Latest: Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
- PEFT: Train only a small subset of parameters, freezing the rest.
- Key considerations: computation flow in LLMs, PEFT fundamentals.
- Four categories:
- Additive: add parameters or adjust activations, no change to base parameters.
- Selective: fine-tune a subset of base parameters (e.g., some layers, heads).
- Reparameterization: map parameters into low-dimensional space for training.
- Hybrid: combinations of the above.
Two Key Issues
-
Computation Flow in LLaMA:
- Pretraining has three parts: Embedding, many Decoder blocks, Output Head.
- Embedding maps text → vectors; Decoder uses MSA + FFN; final linear + softmax outputs token distribution.
- Uses RoPE for positional embeddings, SiLU activation in FFN.
- Softmax produces token probabilities:
-
Overview on PEFT:
- Additive: add modules.
- Selective: update subsets of parameters.
- Reparameterized: low-rank updates merged after training.
- Hybrid: combined approaches.

Evaluation Tasks
- General benchmarks: GLUE (CoLA, SST-2, MRPC, STS-B, QQP, MNLI, QNLI, RTE, WNLI)
- QA benchmarks: OpenBookQA, BoolQ, ARC-easy, ARC-challenge
- Reasoning & commonsense: PIQA, SocialQA, HellaSwag, WinoGrande
- Real-world scenarios: SharedGPT, Azure Function Trace, Gamma process
Categories of PEFT
1. Additive PEFT
- Freeze base model, add/train small modules.
- Examples:
- Adapters: bottleneck layers with up/down projection.
- Soft Prompts / Prefix Tuning: prepend trainable vectors to guide attention.
- IA³ / SSF: scale and shift layers after MSA/FFN/Norm, minimal overhead.
2. Selective PEFT
- Train a subset of existing parameters, using masks.
- Examples:
- Diff Pruning: train only difference vector $\delta$.
- FishMask / Fish-Dip: select via Fisher information.
- BitFit: fine-tune only bias terms.
- Child-tuning / PaFi / SAM: selective structural pruning.
3. Reparameterized PEFT
- Low-rank updates merged with base weights after training.
- Representative: LoRA:
- Extensions: DyLoRA (dynamic ran