How to Train a Chinese Tokenizer Model Using SentencePiece
What is SentencePiece
Tokenizer
-
Converts a sequence of characters into a sequence of numbers.
-
Three levels of granularity: word, char, subword (balances advantages of word and char levels).
-
Common subword algorithms:
- BPE (Byte-Pair Encoding): Start with characters, iteratively merge the most frequent consecutive token pairs until reaching the target vocabulary size.
- BBPE: Extends BPE from character to byte level. Each byte is treated as a character, limiting the base vocabulary to 256 symbols. Pros: cross-lingual vocab sharing, smaller vocab size. Cons: for Chinese, sequence length increases significantly.
- WordPiece: A variant of BPE based on probability. Instead of merging the most frequent pair, it merges the pair that maximizes the language model likelihood.
- Unigram: Initializes a large vocabulary and removes tokens iteratively based on a language model until the desired vocabulary size is reached.
- SentencePiece: Google’s open-source subword toolkit. Treats sentences as a whole, ignoring natural word boundaries. Supports BPE or Unigram algorithms and treats spaces as special characters.
-
Popular model tokenizers:
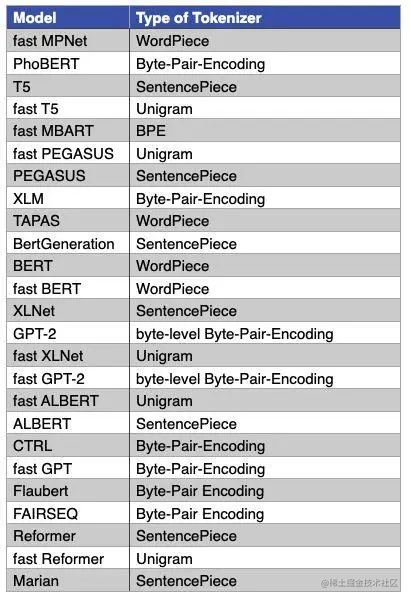
Introduction to SentencePiece
- SentencePiece is an unsupervised text tokenizer and detokenizer for neural text generation systems with a fixed vocabulary before training.
- Implements subword units (BPE, Unigram LM) and can train directly from raw sentences. This allows creating an end-to-end, language-independent NLP system.
- Supports Chinese, English, Korean, or mixed-language text
- Pure data-driven end-to-end pipeline
- No language-specific preprocessing required (useful for multilingual systems)
Features:
- Train directly from raw sentences
- Predefined vocabulary size
- Spaces treated as basic symbols
Environment Setup
SentencePiece has two parts: model training and model usage.
Build and Install SentencePiece CLI
Dependencies:
- cmake
- C++11 compiler
- gperftools (optional, 10–40% speedup)
Install build tools on Ubuntu:
sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev
Build and install:
git clone https://github.com/google/sentencepiece.git
cd sentencepiece
mkdir build
cd build
cmake ..
make -j $(nproc)
make install
ldconfig -v
Check CLI usage:
spm_train --help
Install Python Wrapper
pip install sentencepiece
Training a Model
- Dataset: “Dream of the Red Chamber” (pre-cleaned)
spm_train --input=train.txt --model_prefix=./tokenizer --vocab_size=4000 --character_coverage=0.9995 --model_type=bpe
Parameters:
--input: Training corpus (comma-separated files, one sentence per line). No need for tokenization or preprocessing. SentencePiece applies Unicode NFKC normalization by default.--model_prefix: Output prefix; generates<prefix>.modeland<prefix>.vocab.--vocab_size: Vocabulary size (e.g., 4000, 8000, 16000, 32000).--character_coverage: Fraction of characters to cover; for rich character sets (Chinese/Japanese) use 0.9995, otherwise 1.0.--model_type: Model type; options:unigram(default),bpe,char,word. Forword, input must be pre-tokenized.
Output files:
ls -al model_path
View vocabulary:
head -n20 vocab_path
Reference: