Paper Notes: Why Do Multi-Agent LLM System Fail?
- MAST-Data: The first multi-agent system dataset to characterize MAS failure dynamics, guiding the development of better future systems.
- Build the first Multi-Agent System Failure Taxonomy (MAST).
- The entire process is divided into 14 distinct failure modes, grouped into 3 categories:
- System Design Issues
- Inter-Agent Misalignment
- Task Verification
- Develop an LLM-as-a-Judge pipeline with high consistency with human annotations.
- Found that the primary cause of MAS task failures is system design issues, which cannot be simply summarized as prompt and LLM limitations.

Some Challenges
- long-horizon web navigation: Agent Workflow Memory, introduces workflow memory. (Agent workflow memory, 2024. URL https://arxiv.org/abs/2409.07429.)
- Programming agentic flows: DSPy (https://arxiv.org/abs/2310.03714)
- Task-solving capabilities: StateFlow state control
The Principles for Agentic System
- Anthropics’s blog: https://www.anthropic.com/research/building-effective-agents
- Kapoor et al. demonstrated how overly complex protocols can hinder proper system functioning. AI agents that matter, 2024. URL https://arxiv.org/abs/2407.01502
MAST-Dataset
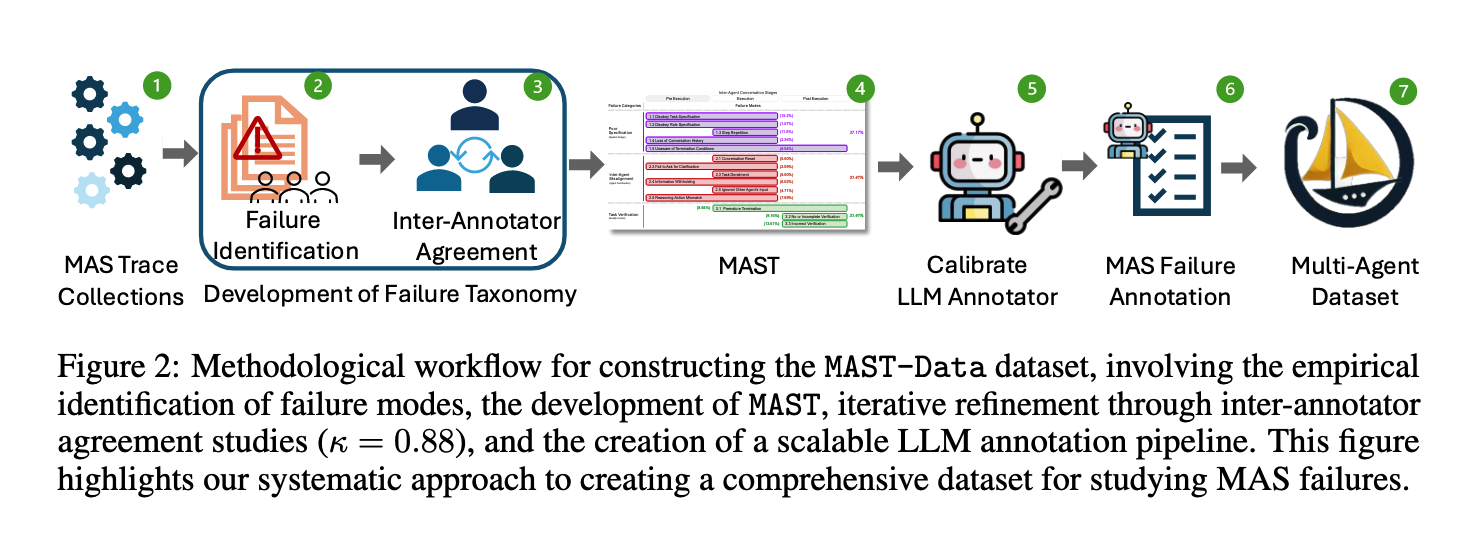
- Determining the root causes of failures requires understanding system dynamics, not just simple detection.
- The lack of a standardized framework with well-defined definitions makes identifying and classifying MAS failures across different systems inconsistent, complicating annotation and cross-system analysis.
- Data collection follows Grounded Theory Analysis (the logic is not entirely clear, but simply put, human experts extract failure sample trajectories from several MAS)
- This GT theory means that no failure categories are defined at all before data collection
- Open Coding: line-by-line annotation of raw trajectories indicating “what went wrong” (identified by humans)
- Constant Comparative Analysis: humans compare various errors to achieve error alignment between different MAS
- Theorizing: ultimately what is needed is
failure mode + definition + boundaries + examples - Theoretical Saturation: when no new error types emerge
- Develop a failure taxonomy MAST to guide personnel in constructing MAST-Data, ultimately forming an IAA protocol through discussion.
- Develop an LLM-as-a-Judge pipeline as an automated annotation tool.
The Multi-Agent System Failure Taxonomy
Three major categories of failures:
- System Design Issues. Failures originate from system design decisions and poor or ambiguous prompt specifications.
- This should be mitigated with minimal high-level objectives and clear user inputs.
- Inter-Agent Misalignment. Failures stem from critical information flow disruptions in agent interactions and coordination during execution.

- Recent system innovations, such as Model Context Protocol (MCP) and A2A, improve agent communication by standardizing message formats from different tool or agent providers. However, even when agents within the same framework communicate using natural language, the errors we observed in FC2 still occur. This suggests a deeper challenge in agent interaction dynamics: a breakdown in “theory of mind,” where agents fail to accurately simulate other agents’ information needs. Addressing this may require structural improvements to the content of agent messages, or enhancements to models’ contextual reasoning and their ability to infer other agents’ information needs, for example through targeted training, as base LLMs are typically not pre-trained for such nuanced inter-agent dynamics. Therefore, robust solutions may involve a combination of improved MAS architectures and model-level advances in communication intelligence.
- Task Verification. Failures involve inadequate verification processes that fail to detect or correct errors, or prematurely terminate tasks.
- Premature termination, incomplete verification, etc., lead to tasks passing surface tests but not deep functional tests.
- Should reference standards from traditional software development.
Towards better Multi-Agent LLM Systems
- To be added later