
分词器(Tokenizer)
-
将字符序列转化为数字序列
-
三种颗粒度:word、char、subword(平衡前两者的优缺点)。
-
常用的subword算法:
- BPE:即字节对编码。其核心思想是从字母开始,不断找词频最高、且连续的两个token合并,直到达到目标词数。
- BBPE:BBPE核心思想将BPE的从字符级别扩展到子节(Byte)级别。BPE的一个问题是如果遇到了unicode编码,基本字符集可能会很大。BBPE就是以一个字节为一种“字符”,不管实际字符集用了几个字节来表示一个字符。这样的话,基础字符集的大小就锁定在了256(2^8)。采用BBPE的好处是可以跨语言共用词表,显著压缩词表的大小。而坏处就是,对于类似中文这样的语言,一段文字的序列长度会显著增长。
- WordPiece算法可以看作是BPE的变种。不同的是,WordPiece基于概率生成新的subword而不是下一最高频字节对。WordPiece算法也是每次从词表中选出两个子词合并成新的子词。BPE选择频数最高的相邻子词合并,而WordPiece选择使得语言模型概率最大的相邻子词加入词表。
- Unigram:它和 BPE 以及 WordPiece 从表面上看一个大的不同是,前两者都是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram Language Model 却是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
- SentencePiece:SentencePiece它是谷歌推出的子词开源工具包,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。SentencePiece除了集成了BPE、ULM子词算法之外,SentencePiece还能支持字符和词级别的分词。
主流的模型采用的分词算法:
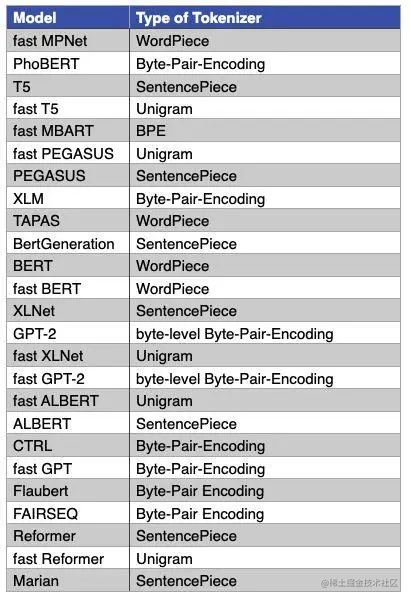
SentencePiece简介
-
SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。
-
SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型(subword model)。 这使得我们可以制作一个不依赖于特定语言的预处理和后处理的纯粹的端到端系统。
- 用它处理中文、英文、韩文甚至混合语言的文本
- 构建一个纯粹的数据驱动、端到端的 NLP 系统
- 不用做语言特定的适配,这对多语言系统特别有用
-
特性:
- 从原始句子开始训练;
- 唯一Token数量是预先确定的;
- 空格被视为基本符号。
环境安装
-
SentencePiece分为两部分:训练模型和使用模型。其中,训练模型部分是用C语言实现的,可编译二进程程序执行,训练结束后生成一个model文件和一个词典文件。
模型使用部分同时支持二进制程序和Python调用两种方式,训练完生成的词典数据是明文,可编辑,因此,也可以用其他任何语言进行读取和使用。
-
从 C++ 源构建和安装 SentencePiece 命令行工具
由于我们需要命令行工具模型训练,因此,我们需要先安装 SentencePiece 命令行工具。
构建 SentencePiece 需要以下工具和库:
- cmake
- C++11 编译器
- gperftools 库(可选的,可以获得 10-40% 的性能提升)
在 Ubuntu 上,可以使用 apt-get 安装构建工具:
1sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev接下来,按如下方式构建和安装命令行工具。
1 2 3 4 5 6 7 8git clone https://github.com/google/sentencepiece.git cd sentencepiece mkdir build cd build cmake .. make -j $(nproc) make install ldconfig -v查看命令使用文档:
1spm_train --help -
使用pip安装sentencepiece库
SentencePiece 提供了支持 SentencePiece 训练和分割的 Python 包装器。 由于后续会基于Python语言使用模型,因此,使用 pip 安装 SentencePiece 的 Python 二进制包。
1pip install sentencepiece
训练模型
-
使用红楼梦作为数据集
-
由于官网只提供英语和日语数据,如果使用中文进行模型训练的话,需要先下载中文训练数据。本文使用 红楼梦(需要自行预先清洗下数据)进行模型训练。
1spm_train --input=train.txt --model_prefix=./tokenizer --vocab_size=4000 --character_coverage=0.9995 --model_type=bpe参数说明:
- –input: 训练语料文件,可以传递以逗号分隔的文件列表。文件格式为每行一个句子。 无需运行tokenizer、normalizer或preprocessor。 默认情况下,SentencePiece 使用 Unicode NFKC 规范化输入。
- –model_prefix:输出模型名称前缀。 训练完成后将生成 <model_name>.model 和 <model_name>.vocab 文件。
- –vocab_size:训练后的词表大小,例如:8000、16000 或 32000
- –character_coverage:模型覆盖的字符数量,对于字符集丰富的语言(如日语或中文)推荐默认值为 0.9995,对于其他字符集较小的语言推荐默认值为 1.0。
- –model_type:模型类型。 可选值:unigram(默认)、bpe、char 或 word 。 使用word类型时,必须对输入句子进行pretokenized。
-
模型输出文件(词表及模型权重):
1> ls -al model_path -
查看词表:
1> head -n20 vocab_path
参考文档: